Prior Projects
Vera: Data Movement Detectives
VERA aims to develop diagnostic tools for data movement, which is the main source of performance and energy inefficiency in parallel software. Technological advances and big data have increased the importance of data and data has become more critical than computation in terms of both energy consumption and performance in a software. Therefore, there is a need for performance tools that automatically detect and measure data movement in the memory hierarchy and between cores.
VERA will develop data movement tools that are much faster, much more comprehensive, much more scalable and highly accurate than previous studies that track and analyze data in parallel programs.
Collaborators: Paul Kelly (Imperial College London)
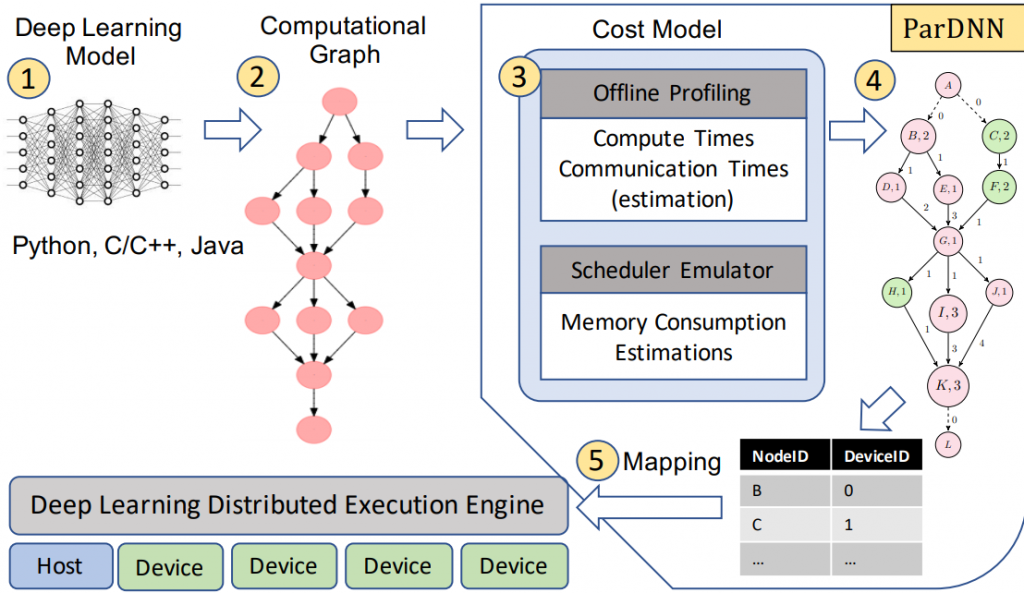
Efficient and Memory Aware Deep Learning
Deep Learning models are compute-and-memory-intensive. Due to their widespread, training them efficiently while obeying the memory constraints of the used processing elements has invaluable benefits. While meeting the memory constraints permits exploring new architectures; efficient training enables conducting faster, cost-and-energy-effective research. This project focuses on applying generic, and system-level optimizations to achieve these two goals.
Collaborators: Wahib Attia (AIST, Japan)
Identifying Intra-node GPU Communication
In single-node multi-GPU systems, communication is a critical programming component and performance contributor. To handle the communication between multiple GPUs, CUDA API offers various data transfer options to the programmer under the hood of Unified Virtual Addressing (UVA), Zero-copy Memory and Unified Memory paradigms. This project focuses on monitoring, identifying, and quantify different types of communication among GPU devices.
The tool is available at https://github.com/ParCoreLab/ComScribe
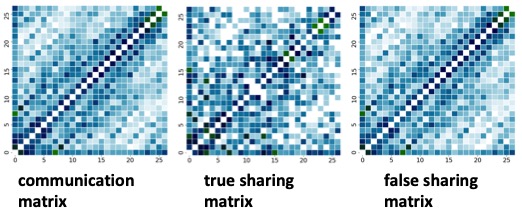
Communication Detection For Inter-Thread Communication
In a multicore environment, inter-thread communication can provide valuable insights about application performance. Literature detecting inter-thread communication either employs hardware simulators or binary instrumentation. Those techniques bring both space and time overhead, which makes them impractical to use on real-life applications. Instead, we take a completely different approach that leverages hardware performance counters and debug registers to detect communication volume between threads. This work is nominated for the best paper and the best student paper at SC19. Tool is available at github.
Collaborators: Milind Chabbi (Uber)
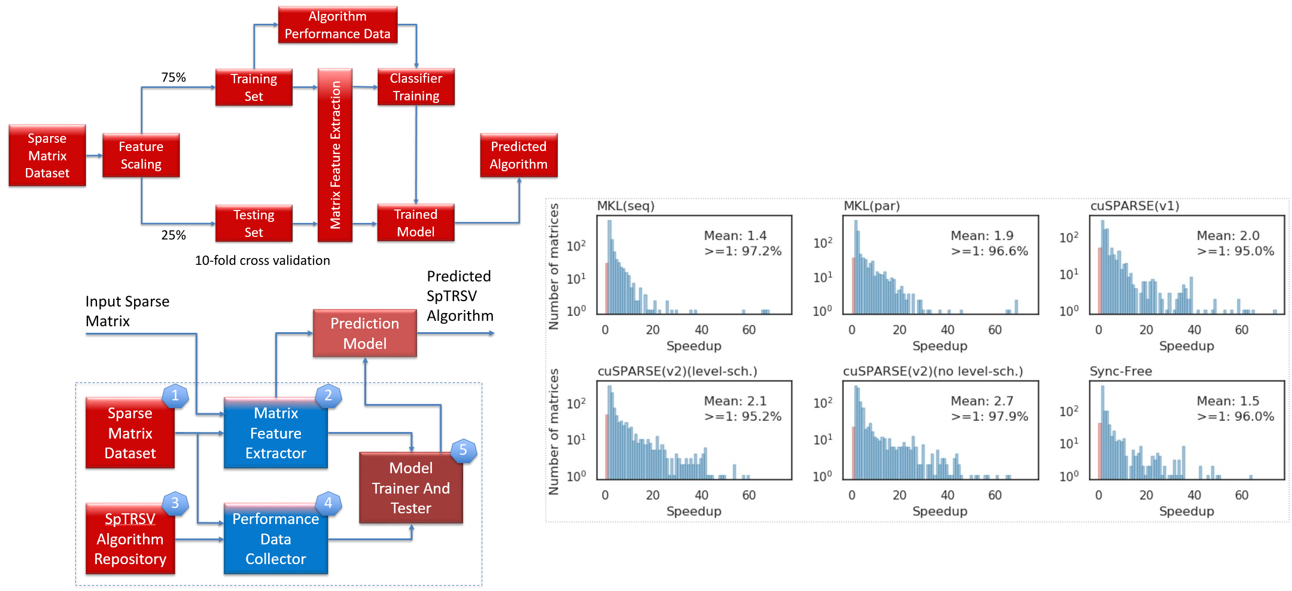
A Prediction Framework for Fast Sparse Triangular Solves
The parallel implementation of SpTRSV is a challenging task due to the sequential nature of the steps involved. Many approaches for efficient SpTRSV on CPU and GPU systems have been proposed in the literature. However, no single implementation or platform (CPU or GPU) gives the fastest solution for all input sparse matrices. In this work, we propose a machine learning-based framework to predict the SpTRSV implementation giving the fastest execution time for a given sparse matrix based on its structural features. The framework is tested with six SpTRSV implementations on a state-of-the-art CPU-GPU machine (Intel Xeon Gold CPU, NVIDIA V100 GPU). Predicted SpTRSV implementations achieve average speedups (harmonic mean) in the range of 1.4–2.7× against the six SpTRSV implementations used in the evaluation.
Our paper received the best artifact award at the prestigious Europar 2020 conference, virtually held at Warsaw, Poland (August 24-28). GitHub, Paper, Presentation, YouTube
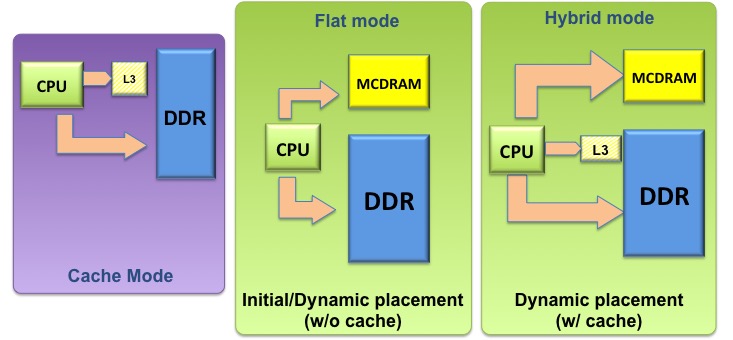
Data Placement On Heterogeneous Memory Systems
Heterogeneous memory systems are equipped with two or more types of memories, which work in tandem to complement the capabilities of each other. We study various data placement scheme to assist the programmer in making decisions about program object allocations on heterogeneous memory systems
TiDA And TiDA-Acc: Tiling Abstraction For Data Arrays For CPU And GPU
TiDA is a programming abstraction that centralizes tiling information within array data types with minimal changes to the source code. The metadata about the data layout can be used by the compiler and runtime to automatically manage parallelism and optimize data locality. TiDA targets NUMA and coherence domain issues on the massively parallel multicore chips.
Collaborators: Tan Nguyen and John Shalf at Berkeley Lab
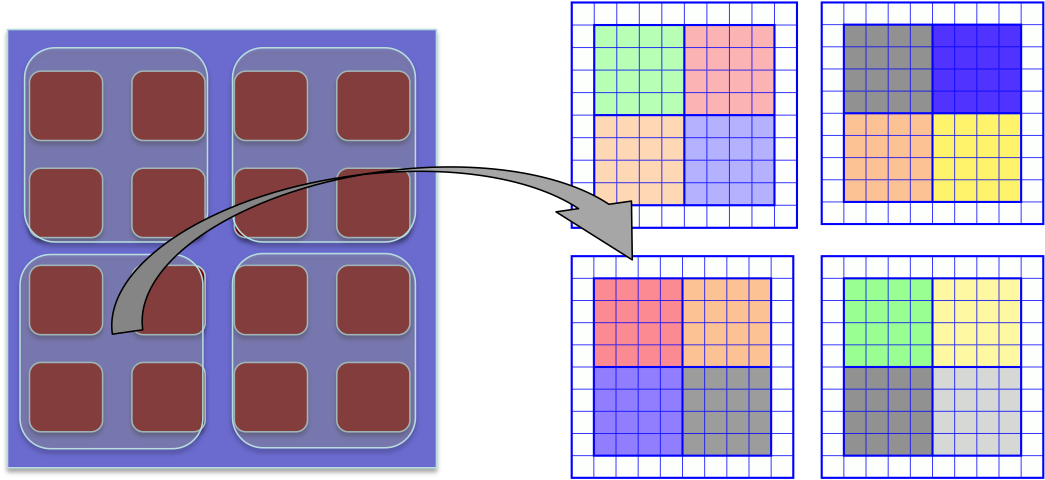
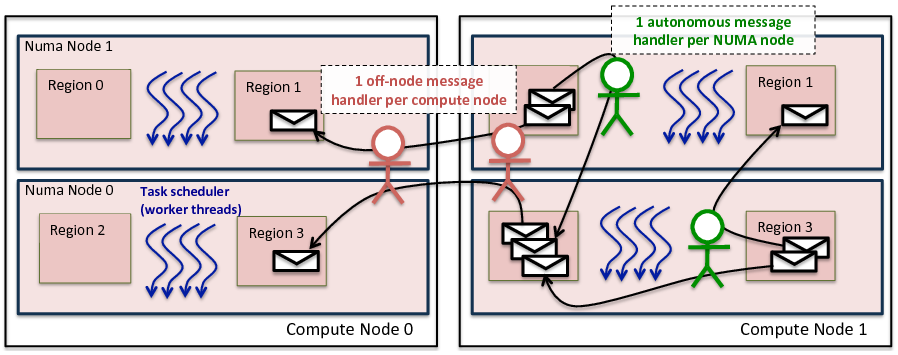
Asynchronous Runtime System For AMR
Perilla is a data-driven task graph-based runtime system that exploits the meta-data information extended from the AMRex AMR framework and TiDA tiling library. Perilla utilizes meta-data of AMRex to enable various optimizations at the communication layer facilitating programmers to achieve significant performance improvements with only a modest amount of programming effort.
Collaborators: Tan Nguyen and John Shalf at Berkeley Lab
EmbedSanitizer: Runtime Race Detection For 32-Bit Embedded ARM
EmbedSanitizer is a tool for detecting concurrency data races in 32-bit ARM-based multithreaded C/C++ applications. We motivate the idea of detecting data races in embedded systems software natively; without virtualization or emulation. This provides more precise results and increased throughput and hence enhanced developer productivity.
More information: https://github.com/hassansalehe/embedsanitizer
Contributors: Hassan Salehe Matar, Didem Unat, Serdar Tasiran
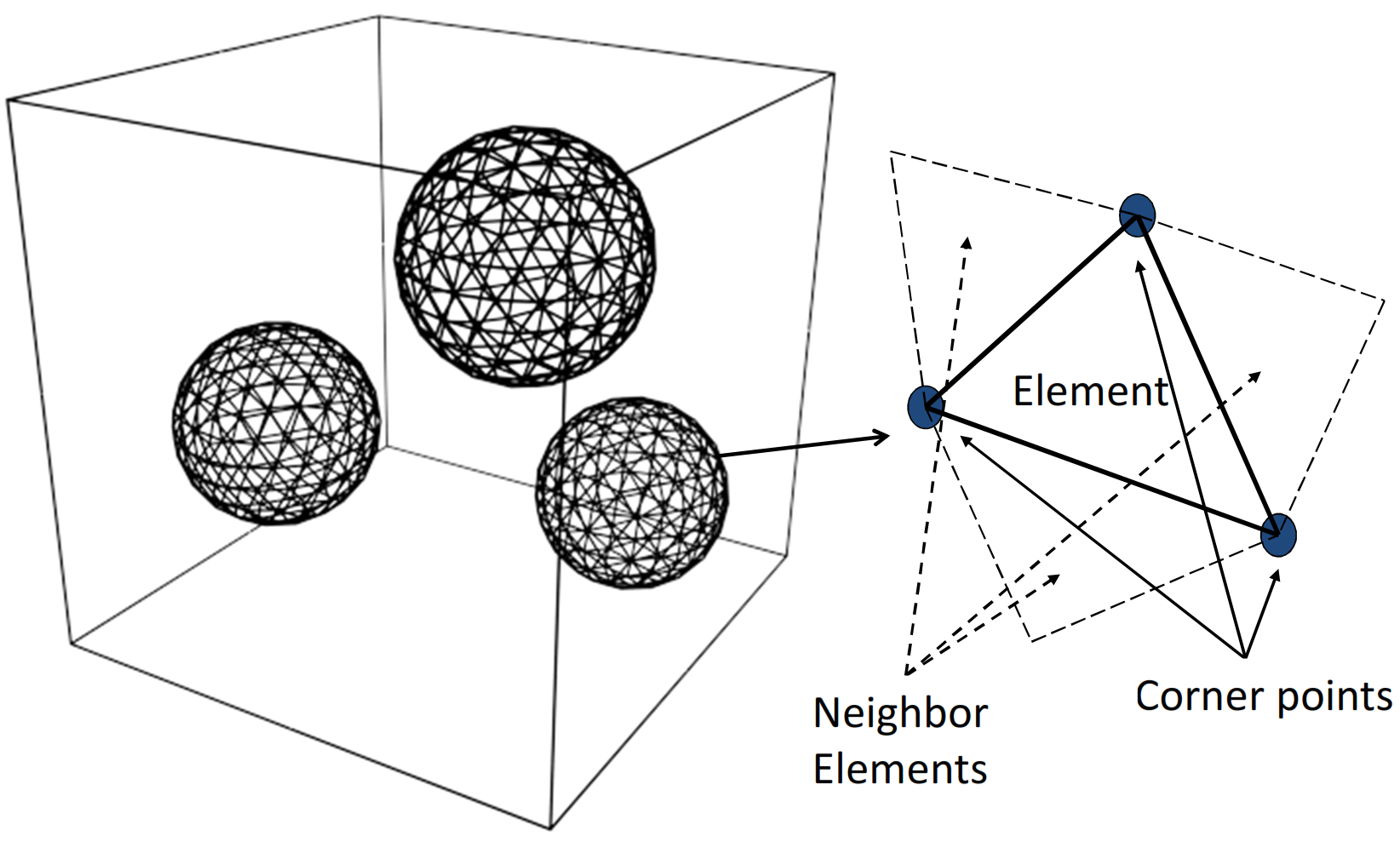
Scalable 3D Front Tracking Method
Front tracking is an Eulerian-Lagrangian method for simulation of multiphase flows. The method is known for its accurate calculation of interfacial physics and conservation of mass. Parallelization of front tracking method is challenging because two types (structured and unstructured) of grids need to be handled at the same time. Scalable 3d front tracking method is implemented to optimize different types of communication that arises with parallel implementation of the method.
Collaborators: Metin Muradoğlu and Daulet Izbassarov at Koç University
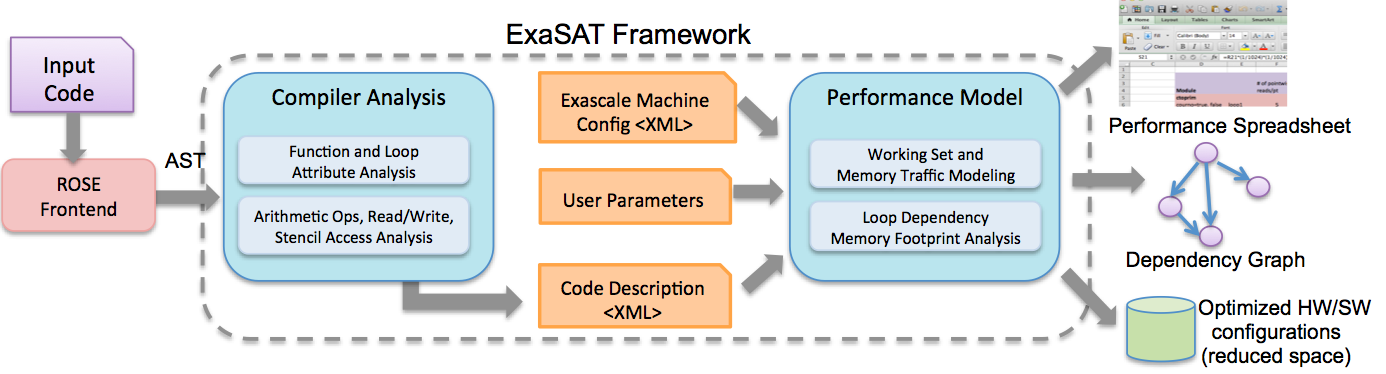
ExaSAT: A Performance Modeling Framework For ExaScale Co-Design
ExaSAT is a comprehensive modeling framework to qualitatively assess the sensitivity of exascale applications to different hardware resources. It can statically analyze an application and gather key characteristics about the computation, communication, data access patterns and data locality. The framewore explores design trade-offs, and extrapolate application requirements to potential hardware realizations in the exascale timeframe (2020). Finally, ExaSAT forms the groundwork for more detailed studies involving architectural simulations of different system design points. Project webiste: http://www.codexhpc.org/?p=98
Collaborators: Cy Chan, John Shalf and John Bell at Berkeley Lab
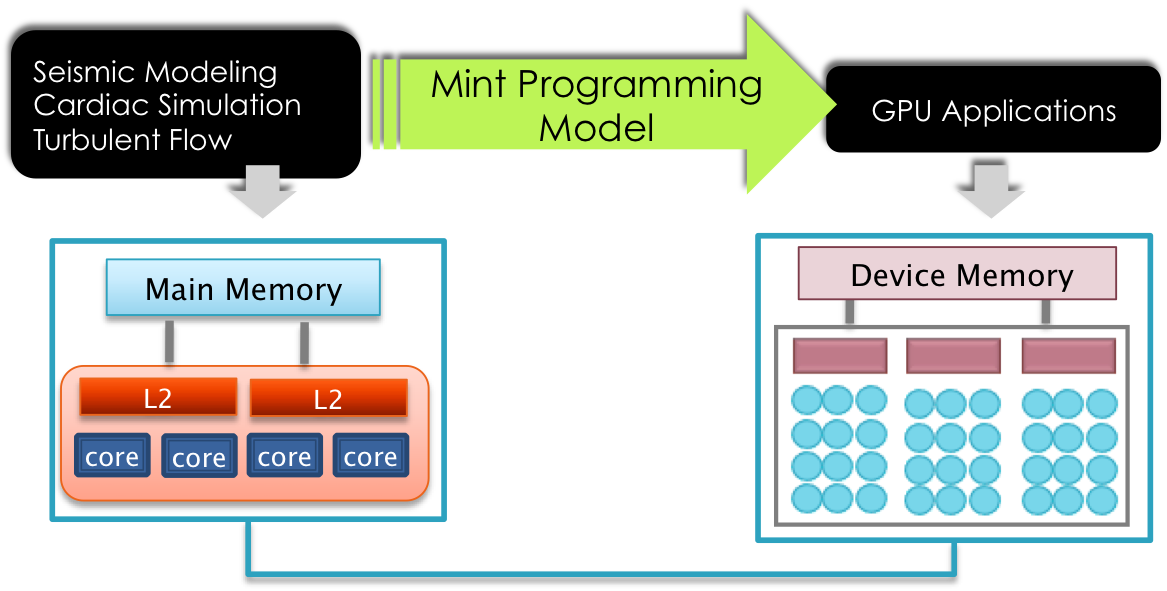
Mint Programming Model For GPUs
Mint is a domain-specific programming model and translator that generates highly optimized CUDA C from annotated C source. Mint includes an optimizer that targets 3D stencil methods. The translator generates both host and device code and handles the memory management details including host-device and shared memory optimizations. For more info, visit Mint website, read our paper and thesis.
Collaborators: Scott Baden at Univ. of California, San Diego and Xing Cai at Simula Research Lab