Ongoing Projects
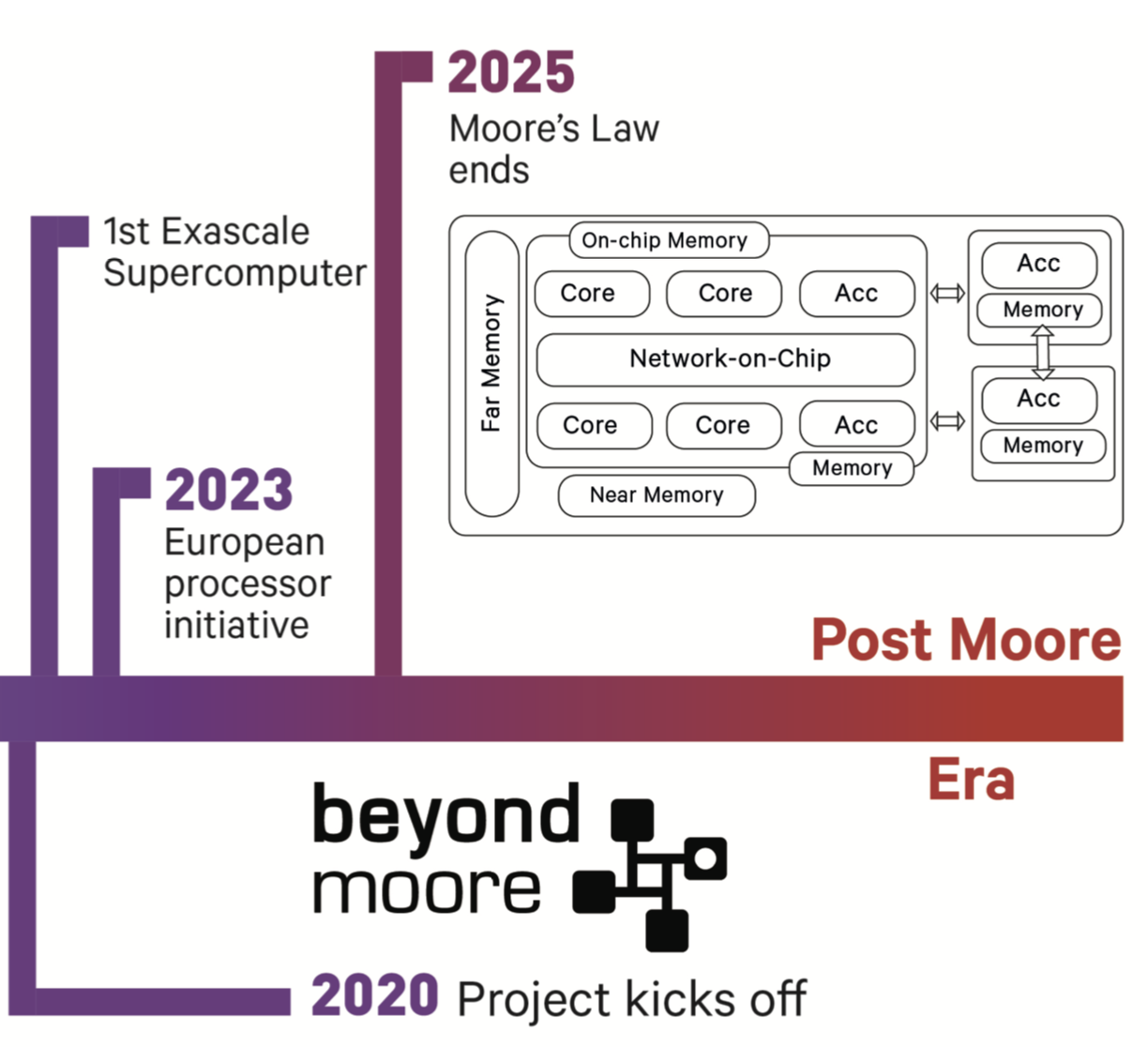
BEYONDMOORE
BEYONDMOORE addresses the timely research challenge of solving the software side of the Post Moore crisis. The techno-economical model in computing, known as the Moore’s Law, has led to an exceptionally productive era for humanity and numerous scientific discoveries over the past 50+ years. However, due to the fundamental limits in chip manufacturing we are about to mark the end of Moore’s Law and enter a new era of computing where continued performance improvement will likely emerge from extreme heterogeneity. The new systems are expected to bring a diverse set of hardware accelerators and memory technologies.
BEYONDMOORE has an ambitious goal to develop a software framework that performs static and dynamic optimizations, issues accelerator-initiated data transfers, and reasons about parallel execution strategies that exploit both processor and memory heterogeneity.
You can find out more about our projects on our GitHub repository here.
Budget: 1.5 Million Euros
INNO4SCALE – aCG: Adaptive CG Algorithm on Large-Scale GPU Systems
The Inno4scale project, titled aCG: Adaptive CG Algorithm on Large-Scale GPU Systems,supported by the EuroHPC Joint Undertaking under the HORIZON-EUROPE-JU-2022-ALG-02 call, seeks to enhance the performance of High-Performance Computing (HPC) applications on current and future European supercomputers. Recognizing the need for a radical redesign of algorithms to leverage the massively parallel and heterogeneous processing capabilities of exascale and post-exascale computers, Inno4scale focuses on developing novel algorithms and their efficient implementation to solve computational problems deemed currently intractable. Through funding targeted innovation studies, Inno4scale aims to create proof-of-concept demonstrators for these groundbreaking algorithms, thereby ensuring the efficient utilization of EuroHPC JU’s supercomputing resources. In this context, Dr. Didem Unat of Koç University’s ParCore Lab, in collaboration with Simula Research Laboratory, has been awarded 200,000 Euros by the Inno4Scale grant. This award will fund a one-year research initiative focusing on advancing parallel programming of iterative solvers in accelerator-rich supercomputers, thereby contributing significantly to the overarching goals of the Inno4scale project.
Collaborators: Simula Research Laboratory
Budget: 200,000 Euros

SPARCITY
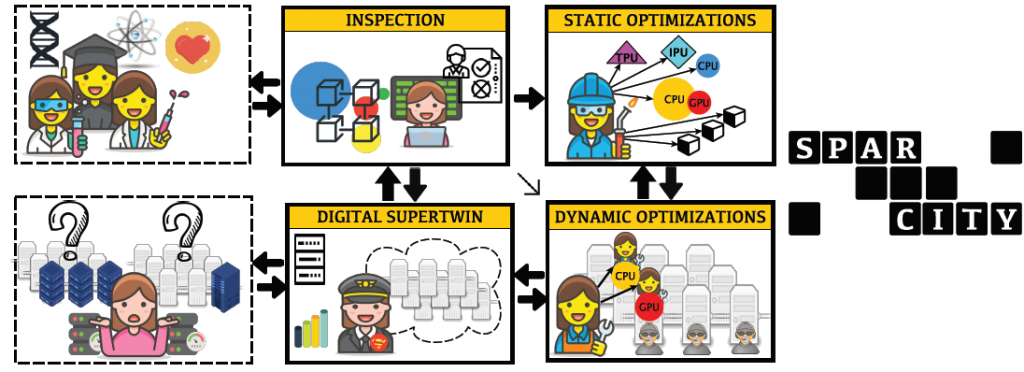
The SparCity project aims at creating a supercomputing framework that will provide efficient algorithms and coherent tools specifically designed for maximising the performance and energy efficiency of sparse computations on emerging HPC systems, while also opening up new usage areas for sparse computations in data analytics and deep learning.
Overall, SparCity is a forward-looking project with a significant contribution to building Europe’s strengths in the application of HPC and related software tools, in the adoption of low-energy processing technologies, and in the development of advanced software and services for its citizens.
For details, visit the project website: http://sparcity.eu/
Budget 2.6 Million Euros
Quantum Annealing Assisted Ant Colony Optimization for Task Assignment Problem
The project attempts to increase the efficiency of solving the task assignment problem by enhancing the classical population-based metaheuristic approach using recently introduced quantum annealing devices. The stochastic nature of the quantum annealing process provides an extra source of diversification essential for a thorough exploration of the search space. Additionally, it rapidly produces a large number of candidate solutions. On the other hand, the classical component of the algorithm is capable to guide the search, which allows ensuring the validity of the solution and to scale the efficiency of assignment at the cost of CPU time and/or the number of quantum annealing device queries.
Collaborators: Anastasiia Butko (Berkeley Lab)